文本以及填空(Cloze)模板处理
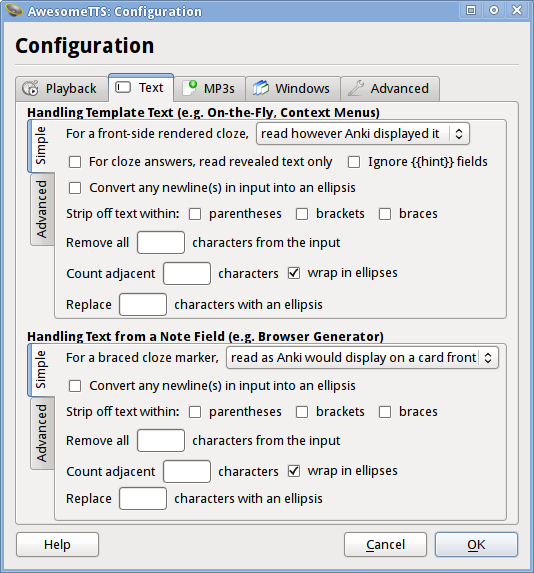
文本处理配置窗口
文本处理允许用户控制AwesomeTTS处理文本的方式,以便获取正确的读音,比如去除一些特殊字符,因为有些语音服务器是无法读取特殊字符的,这时候就需要AwesomeTTS把文本发送到语音服务器之前进行预处理。
对于一般用户AwesomeTTS已经预设了一些处理策略,当然对于高级用户也可以自定义适合自己的文本处理策略。
文本处理机制可以帮助那些喜欢在卡片中展示一些特殊文本但又不想让AwesomeTTS读出来的用户,当然你也可以把不需要发音的部分单独放到一个字段,作为本机制的一个替代方案。
处理模板文本(Handling Template Text)
此部分用于配置AwesomeTTS处理模板中文本的策略,即<tts>标签中的内容。
处理后的结果不会显示在屏幕上,而是反应在获取读音的结果上。
处理字段中的文本(Handling Text from a Note Field)
此部分用于配置AwesomeTTS处理字段中文本,即利用卡片浏览器等方式批量生成音频的时候,处理即将生成音频文件的文本格式。
结果同样反应在生成的MP3等媒体文件中。
预设处理方案
填空(Cloze)模板处理
填空模板是Anki自带的一套模板,把特定的字符串用[…]替代,实现填空题的功能,而当需要获取填空字段发音(即含有{{c1::xx}})的时候,AwesomeTTS可以按照如下方式进行处理:
| 如果你的字段中含有: | Hello {{c1::world}}! Hello {{c1::world::place}}! |
| 按照Anki的约定,默认会在卡片正面生成: | Hello [...]! Hello [place]! |
| 如果选择“read however Anki displayed it” 或者 “read as Anki would display on a card front”,则AwesomeTTS实际上会把右边的文本发送到语音服务器 | Hello ... ! Hello place! |
| 如果选择“read w/ hint wrapped in ellipses” 或者“replace w/ hint wrapped in ellipses”,则AwesomeTTS实际上会把右边的文本发送到语音服务器 | Hello ... ! Hello ... place ... ! |
| 如果选择“replace w/ deleted text” (notes only),则AwesomeTTS实际上会把右边的文本发送到语音服务器 | Hello world! Hello world! |
| 如果选择“read as an ellipsis, ignoring hint”或者“replace w/ ellipsis, ignoring both”,则AwesomeTTS实际上会把右边的文本发送到语音服务器 | Hello ... ! Hello ... ! |
| 如果选择“remove entirely”,则AwesomeTTS实际上会把右边的文本发送到语音服务器 | Hello ! Hello ! |
注意如果你把填空字段放入了<tts>标签中,然后在卡片背面只想获取答案的发音的话可以勾选上“For cloze answers, read revealed text only”。
{{hint}}字段
如果你在<tts>标签中加入了{{hint}}字段,可以通过勾选“Ignore {{hint}} fields”选项来忽略掉{{hint}}内容的发音。
注意这里的{{hint}}字段和Cloze中的{{c1::xx::hint}}不同。
字符计数(Counting Adjacent Characters)
你可以用这个功能让AwesomeTTS告诉你空白处有多少个字符。
比如,你在字段填入The grass is always _______ on the other ____,然后你在 “count adjacent characters” 后填入_并且勾选上“wrap in ellipses”,这样AwesomeTTS读出来的句子是The grass is always ... 7 ... on the other ... 4 ...。也就是把_替换成了数字。
自定义策略(Advanced Handling)

自定义文本处理策略窗口
如果你有一些特殊的字符需要在获取发音前过滤掉或者进一步加工,那么可以使用自定义策略(Advanced Handling)来配置适合自己的一套处理方式。
正则表达式(regex)选项框允许你使用正则表达式进行匹配,比如用\b来匹配一个单词边界,具体语法请参考度娘:sleeping:匹配到的文本会被第二个文本框中的内容替换掉。
统一码(unicode)选项框允许匹配非ASCII标准码表中的字符,如果日语韩语等。
如果你想替换掉匹配到的文本,那么直接把第二个文本框留空即可。
AwesomeTTS会在所有默认方案处理完毕后才按顺序允许用户自定义的策略。
其他注意事项
- 一般的语音服务器会吧
...(ellipsis)当成一个句子停顿,所以AwesomeTTS会把填空占位符等特殊字符处理成省略号以免出错,当然根据不同的语音服务器可能有差别,用户可以按需求自己定义。 - AwesomeTTS总是会在获取发音前移除掉
[sound]标签和HTML标签。 - 由一般的
[](bracket)或者{}(brace)包裹的文本会和填空模板中的[]或者{}符号分开处理,所以同时使用不会发生冲突。 - 当处理剪贴板中的文本中时(比如使用笔记编辑器预填充字段),一些策略也是可以生效的。
- 当直接输入文本到文本框中时候,AwesomeTTS会周期性地移除多余的空格。
- 覆盖掉一些特殊符号(
()parantheses、[]brackets、{}braces)包裹的文本可能会带来意想不到的结果。比如如果选中替换掉()包裹的文本,那么Hello world! (English {somewhat) informal}实际上会被处理成Hello world! informal}:worried: - 大家肯定会对AwesomeTTS处理文本的顺序很感兴趣,实际上AwesomeTTS会按照如下顺序处理文本:
- 按照用户的设置处理填空模板
- 总是移除所有hint字段的激活链接(即
Show XX,需要包裹在<tts>标签中才有效) - 如果用户勾选“Ignore {{hint}} fields”则移除所有hint字段内容
- 如果用户勾选“Convert any newline(s) in input into an ellipsis”则转换所有换行符为省略号
- 总是移除所有HTML标签
- 总是移除所有
[sound]标签内容 - 总是移除所有含有音频的路径文本
- 如果用户选中“Strip off text within:parentheses”则移除所有被
()包裹的文本 - 如果用户选中“Strip off text within:brackets”则移除所有被
[]包裹的文本 - 如果用户选中“Strip off text within:braces”则移除所有被
{}包裹的文本 - 按照用户设定移除匹配到的文本
- 按照用户设定计算匹配到的字符数量
- 按照用户设定替换掉匹配到的文本
- 按照用户定义的顺序执行自定义文本处理策略
- 总是移除多余的括号
- 总是把连续的空格转换成一个空格
- 总是移除首尾空格